Animals
Animals Animation
Animation Art of Playing Cards
Art of Playing Cards Drugs
Drugs Education
Education Environment
Environment Flying
Flying History
History Humour
Humour Immigration
Immigration Info/Tech
Info/Tech Intellectual/Entertaining
Intellectual/Entertaining Lifestyles
Lifestyles Men
Men Money/Politics/Law
Money/Politics/Law New Jersey
New Jersey Odds and Oddities
Odds and Oddities Older & Under
Older & Under Photography
Photography Prisons
Prisons Relationships
Relationships Science
Science Social/Cultural
Social/Cultural Terrorism
Terrorism Wellington
Wellington Working
Working Zero Return Investment
Zero Return InvestmentWe're Viewing More Pages
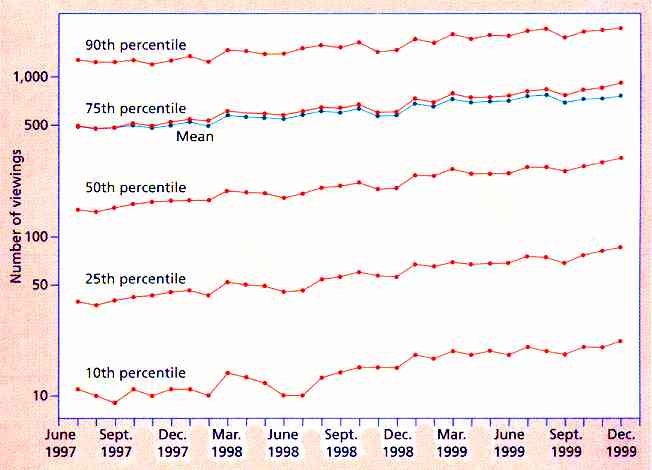
Identifying Web Browsing Trends and PatternsThe Internet "browser"... is the piece of software that puts a message on your computer screen - Dave Barry Surfing on the Internet is like sex; everyone boasts about doing more than they actually do. - Tom Fasulo by Alan L Montgomery and Christos Faloutsos, Carnegie Mellon University Since it entered the popular culture in 1994, the World Wide Web has grown from approximately two million servers to more than 110 million in 2001, according to the Internet Software Consortium. Jupiter Media Metrix, an Internet research company, estimates that during this same period, the number of US home web users has likewise increased from 3 million to more than 89 million. Has this phenomenal growth resulted in fundamental changes in the way users browse the web? To address this question, we analysed a sample of more than 20,000 Internet users who accessed the web from July 1997 through December 1999. This nationally representative data set collected by Jupiter Media Metrix is unique because it was gathered from users' computers, not servers, thus it is immune to caching problems present in other Web usage studies. Exponential GrowthOne straightforward measure of Internet activity is the number of viewings by a web user per month. A viewing means that the user's browser window displays a URL. Due to caching, the number of viewings always equals or exceeds the number of requests or hits that the server logs. For example, the median number of viewings per month in December 1999 was 310, more than twice the 150 viewings recorded in July 1997. During this same period, the number of web users increased 120%, from 28 million to 62 million.
Figure 1 - Distribution of monthly web viewings on a logarithmic scale. Our study suggests not only that the number of web users is increasing, as expected, but also that each user is viewing more pages. As the logarithmic scale in Figure 1 shows, the increase in viewings per month is fairly linear, indicating exponential growth. If the median continues to grow at the current rate of 2.4% per month, the median user's viewings will double every 30 months. This trend resembles Moore's Law, which states that transistor density on integrated circuits will double every 18 months. More, Not Longer, SessionsExamining web usage on a session-by-session basis rather than monthly presents a different picture. A session is a period of sustained Internet usage; a new session begins when the user has not accessed the web for more than two hours. The median number of sessions during December 1999 was four. If the present growth rate of 1.4% per month continues, the average number of sessions will double in a little more than four years. However, the median number of viewings per session in December 1999 was 48, only a slight increase from 42 in July 1997. By decomposing the number of viewings into sessions and the number of viewings per session, we found that growth in web activity is primarily due to more frequent, not longer, browsing sessions. Small but Persistent Domain ViewingContrary to expectations, the explosive growth in web sites and the online information they provide have not encouraged users to examine a wider range of sources. In fact, the data indicates that users look at a fairly small number of sites relative to the number of viewings. The median number of domains viewed per session is six. Although the median number of hosts visited increased steadily from 14 in July 1997 to 25 in December 1999, the ratio of viewings to domains viewed remained fairly steady. Therefore, we can attribute the increase in domains viewed to the increased number of sessions, not to an increased propensity of users to search out new domains within a session. Frequent RevisitsUsers revisit the same web sites frequently. For example, during December 1999, users revisited 54% of URLs at least once during a session. Of the URLs that users revisited, 35% were viewed consecutively (two viewings of the same page occurred in a row), 22% had one viewing in between (the user likely returned to the page through the back button), and the remaining 43% had more than one viewing in between. Users revisit Web domains even more frequently than pages. Our study revealed that users revisit a domain within one viewing 75% of the time. During the study's entire 2½-year period, the probability of a user revisiting a domain during a session remained between 89 and 91%. Web Browsing PatternsOur study showed that URL browsing patterns follow power laws, which are characterised by the relationship y = xa, in which x and y are the variables of interest - for example, force and distance in Newton's law of gravity. A popular distribution with this property is the Zipf distribution. The Zipf distribution describes several web browsing behaviours that are highly skewed, including how often a user revisits a URL within a session and the number of viewings a user makes before revisiting a URL or a domain. These distributions also remained stable during the study period in spite of the strong growth in usage. The Zipf distribution of URL revisitations is somewhat analogous to the Zipf word usage pattern. We repeat certain words such as "the" extensively, while we use other unique words infrequently. These infrequently used words manifest a long tail in the Zipf distribution. Similarly, URLs form the web user's vocabulary. The huge diversity of web pages offers a large vocabulary for use in browsing the Internet. But browsers constantly reuse certain pages, perhaps as a navigational tool for moving to other pages, and they use other unique pages less frequently. The empirical trends we observed yielded several surprises. Many web browsing patterns, such as the number of pages and domains a user views during a computer session, have remained stable. Although overall Internet usage has grown exponentially, the time that an individual browses online has increased at a slower rate. Also, despite dramatic changes in its size and content, the way people interface with the web has not significantly changed. Users remain loyal to hosts and persistent in their viewing habits. These findings demonstrate that it is important to examine how users interact with the Internet as well as changes in the medium itself. In addition, future statistical measurements of browsing patterns must move beyond simple averages, which heavy users tend to skew, to capture the Internet population's growing diversity. Alan L Montgomery is an associate professor at the Graduate School of Industrial Administration at Carnegie Mellon University. Contact him at
alan.montgomery@cmu.edu. Source: Computer: Innovative Technology for Computer Professionals July 2001
Company Will Monitor Phone Calls to Tailor Ads
by Louise Story Companies like Google scan their e-mail users’ in-boxes to deliver ads related to those messages. Will people be as willing to let a company listen in on their phone conversations to do the same? Pudding Media, a start-up based in San Jose, California, is introducing an Internet phone service today that will be supported by advertising related to what people are talking about in their calls. The web-based phone service is similar to Skype’s online service — consumers plug a headset and a microphone into their computers, dial any phone number and chat away. But unlike Internet phone services that charge by the length of the calls, Pudding Media offers calling without any toll charges. The trade-off is that Pudding Media is eavesdropping on phone calls in order to display ads on the screen that are related to the conversation. Voice recognition software monitors the calls, selects ads based on what it hears and pushes the ads to the subscriber’s computer screen while he or she is still talking. A conversation about movies, for example, will elicit movie reviews and ads for new films that the caller will see during the conversation. Pudding Media is working on a way to e-mail the ads and other content to the person on the other end of the call, or to show it on that person’s cellphone screen. "We saw that when people are speaking on the phone, typically they were doing something else," said Ariel Maislos, chief executive of Pudding Media. "They had a lot of other action, either doodling or surfing or something else like that. So we said, ‘Let’s use that’ and actually present them with things that are relevant to the conversation while it’s happening." The company’s model, of course, raises questions about the line between target advertising and violation of privacy. Consumer-brand companies are increasingly trying to use data about people to deliver different ads to them based on their demographics and behaviour online. Pudding Media executives said that scanning the words used in phone calls was not substantially different from what Google does with e-mail. Still, even some advertising executives were wary of the concept. "We can never obtain too much information from the targets, and I would love to get my hands on that information," said Jonathan Sackett, chief digital officer for Arnold Worldwide, a unit of the advertising company Havas. "Still, it makes me caution myself and caution all of us as marketers. We really have to look at the situation, because we’re getting more intrusive with each passing technology." Mr Maislos said that Pudding Media had considered the privacy question carefully. The company is not keeping recordings or logs of the content of any phone calls, he said, so advertisements only relate to current calls, not past ones, and will only arrive during the call itself. Besides, Mr Maislos said, he thought that young people, the group his company is focusing on with the call service, are less concerned with maintaining privacy than older people are. "The trade-off of getting personalised content versus privacy is a concept that is accepted in the world," he said. Mr Maislos founded Pudding Media with his brother, Ruben. Each had spent several years doing intelligence work for the Israeli military. Before Pudding Media, Ariel Maislos ran a broadband company called Passave, which he sold in May 2006 to PMC-Sierra, a maker of computer chips for telecommunications equipment, for $300 million. Richard Purcell, a former chief privacy officer at Microsoft, is an adviser to Pudding Media, Ariel Maislos said. To give the ads greater accuracy, Pudding Media asks users for their sex, age range, native language and ZIP code when they sign up. For now, the company is running ads that are sold by a 3rd-party network, but Pudding Media plans to also sell its own ads in a few months. Advertisers pay based on how often a user click on their ads, and a spokeswoman said the rates were similar to the cost-per-click prices in Google’s AdSense network. Pudding Media plans to add other payment models, like charging for each ad impression or by the number of calls an ad generates to the advertiser. As the company’s software listens in on conversations, it filters out explicit words in determining which ads to select, so that content and ads will not be shown with those inappropriate words. Pudding Media would not elaborate, beyond saying that these were "keywords with profanity and things you wouldn’t want a 13-year-old to hear." While the calling service only works through computers for now, Mr Maislos said he saw the potential to use it with cellphones. The company is offering the technology to cellphone carriers to allow their customers to enjoy free calls in exchange for simultaneously watching contextually relevant ads on their screens. Callers can try Pudding Media at thepudding.com, dialing any number in North America. Because the service has so far been in a quiet beta test, the company would not say how many people have tried it so far. Pudding Media is also trying to sell the technology to web publishers and media companies that would like to offer readers free calls and content related to those calls. A news site, for example, could show only its own articles and ads to people as they talked to friends. Mr Maislos said that during tests he noticed that the content had a tendency to determine conversations. "The conversation was actually changing based on what was on the screen," he said. "Our ability to influence the conversation was remarkable." Source: nytimes.com 24 September 2007
Better Website Design: Scents and SensibilityIf websites are built without bricks or mortar, why does navigating around them so often feel like bashing your head against a wall? Yet frequently it does, and as Jakob Nielsen, one of the gurus of the World Wide Web, points out: "On the Internet, ease of use comes first and transfer of money comes second. Revenues on the web are determined almost completely by usability." It is hardly surprising, therefore, that groups of researchers around the world are trying to devise scientific methods that can make the web easier to use. One such group is based at Xerox’s Palo Alto Research Centre in California, and is led by Ed Chi and Stuart Card. Dr Chi and Dr Card take their inspiration from the science of ecology. Dr Card, a cognitive psychologist, reckons that a user "forages" through a website in search of a piece of information in a manner similar to that employed by an animal foraging through a forest in search of food. Watch the user’s foraging behaviour (his "clickpath") closely enough, and you can work out what "scent" he is chasing, and thus what kind of information he is after. For example, if a user begins by looking at a article on romantic dinners and winds up trying to purchase espresso ice-cream, he (or, in this case, perhaps she) is more likely to follow up by clicking to an article selling perfume or candles than to an article offering pencils or glue. Sites such as that of Amazon.com, the best-known online retailer, already use programs that guess what else a user might want, based on his previous clickpath. This allows the site to work out which products a user ought to find most enticing, and to recommend them. But to assess a site’s usability, Dr Chi has created a program that does the opposite. Given a target, this program, known as "Bloodhound", predicts the clickpath that a user would take to get there. At a conference on computer/human interaction held by the Association for Computing Machinery in Seattle earlier this month, Dr Chi explained how his method works. Bloodhound begins by taking a "snapshot" of all the words on a website, and of all the links connecting the site’s pages. It then assigns a "smell" to each link. This smell is a mathematical formula known as a vector, and is composed of three elements. The first contains the words of the link itself (the highlighted text that a user clicks on to get to the page). The second contains the sentence leading up to the link. The third contains the article that the link leads to. Vectors can be compared mathematically to see how similar they smell. This is done by checking how many words each element in one has in common with the elements in the other — with the proviso that matches between first elements have higher value than matches between second elements, and second-element matches count more than third-element matches. When Bloodhound is let loose on a site by feeding it with a word or phrase, such as a product name (the digital equivalent of waving a fugitive’s handkerchief under its nose), it follows the scent trail from article to article by looking for the link on each article that smells most like its target. If it easily gets to the article intended by the designer of the website as the destination of a real user who had the same target in mind, that points to good site design. If it weaves from article to article before arriving — or, worse still, fails to arrive at all — that suggests a site that will leave users frustrated and confused. Naturally, such a process is useful only to the extent that the computer program searches in the same way that a person would. To test that it does, Dr Chi compared the clickpaths that Bloodhound followed with those of actual, human users, and found that they matched quite well. The current way of rating the ease with which a website can be navigated involves assembling a team of human testers, briefing them, getting them to perform a set of searches that they are not really interested in, collecting data on their failures and successes, and analysing it. Not only can the bill for such an exercise add up to as much as $25,000; it also involves doing what most geeks would rather avoid at all costs — working with people, who are consistently inconsistent in their likes and dislikes. At a couple of thousand dollars a pop, Dr Chi’s software should provide a welcome alternative. Source: The Economist print edition 26 April 2001 © The Economist Newspaper Limited; all rights reserved.
For IT-related articles on snooping, usage, the future, e-diaries, piracy, flickers, cyborgs, browsing, trends, jokes, philosophic agents, artificial consciousness and more, press
the "Up" button below to take you to the Table of Contents for this Information and Technology section. |