Animals
Animals Animation
Animation Art of Playing Cards
Art of Playing Cards Drugs
Drugs Education
Education Environment
Environment Flying
Flying History
History Humour
Humour Immigration
Immigration Info/Tech
Info/Tech Intellectual/Entertaining
Intellectual/Entertaining Lifestyles
Lifestyles Men
Men Money/Politics/Law
Money/Politics/Law New Jersey
New Jersey Odds and Oddities
Odds and Oddities Older & Under
Older & Under Photography
Photography Prisons
Prisons Relationships
Relationships Science
Science Social/Cultural
Social/Cultural Terrorism
Terrorism Wellington
Wellington Working
Working Zero Return Investment
Zero Return InvestmentPrivate and Interactive
A Medium Made for PornAmerica Online customers are upset because the company has decided to allow advertising in its chat rooms. - Jay Leno
by Michael Learmonth The Web, as it turns out, is a medium made for porn. It's private, anonymous, and interactive. By migrating to the web, porn tapped an enormous pool of consumers, most of whom seem to be e-porn surfing during work hours, when 70% of porn surfing takes place. While there is no definitive measurement, many analysts agree that men seeking pornographic material account for about 40% of the searches conducted on the Internet each day. Since images and video take up so much more bandwidth than, say, email, porn surfers probably consume close to 70% of the Internet's capacity. These surfers and millions like them changed the fortunes of many Silicon Valley corporations, large and small. Indeed, without porn, the economic miracle of the second half of the 1990s would have been much more of a yawner. There would be fewer people on the bustling streets of San Jose and Palo Alto, and fewer swanky restaurants. More homes would still be in the six-figure price range, and commute times would be shorter. Sports figures, not Internet geeks, would appear in beer commercials; the stock market would be table conversation for few people other than brokers or retirees. Bus ads and billboards would again carry water conservation messages, presidential candidates would raise their money in Texas and Hollywood, and Time magazine could go back to covering global warming and international politics. Yes, the seedy currency of stroke mags has emerged as a critical enabler of the New Economy, a course of early revenues that capitalises R&D, turns young companies profitable, pushes up the salaries of working stiffs, and turns the luckiest of the bunch into millionaires or billionaires. But don't expect to read about it in annual reports. Even though demand for pornography oh the Web fuels profits in Silicon Valley, the heart of the porno-industrial complex remains hidden beneath the floorboards, even as its heart beats in the air-conditioned router rooms, the executive suites and the boardroom. Source: Anderson Valley Advertiser 1 March 2000
A different take... Study Fnds Web Isn't Teeming with Sex: Analysis Shows about 1% of All Pages Have Adult Contentby Elise Ackerman A confidential analysis of Internet search queries and a random sample of Web pages taken from Google and Micrsoft's giant Internet indexes showed that only about 1% of all web pages contain sexually explicit material. The analysis was presented in a federal court hearing last week in Philadelphia in a suit brought by the American Civil Liberties Union against US Attorney General Alberto Gonzales and obtained Monday by the Mercury News. The ACLU said the analysis, by Philip B Stark, a professor of statistics at the University of California-Berkeley, did not appear to substantially help the Justice Department in its effort to prove that criminal penalties are necessary to protect minors from exposure to sexually explicit information on the Internet. The Justice Department had commissioned the study as part of an effort to resurrect the Children's Online Protection Act, which was signed by President Clinton in 1998, but was immediately challenged by the ACLU. A federal district court in Philadelphia and a federal appeals court banned enforcement of the law. In June 2005, the Supreme Court upheld the ban for constitutional reasons but sent the case back to district court for more fact finding regarding Internet filters. "One of the things we think came out of the government's study is that the chance of running into graphic content on the Web when filters are on is extremely low," said Catherine Crump, staff attorney at the American Civil Liberties Union. Stark's study found that only 6% of all queries returned a sexually explicit website, despite the consistent popularity of queries related to sex. It also found that the filters that did the best job blocking sexually explicit content also inadvertently blocked lots of content that was not explicit. Government witnesses argued that while the percent of sexually explicit web pages was small, it still amounted to a huge number. "A lot of sexually explicit material is not blocked by filters," Stark wrote in the conclusion to his study. Attorneys for the Justice Department were not available for comment Monday afternoon. The 8-year-old lawsuit ignited widespread public debate last year after Google objected to a subpoena it had received to turn over billions of website addresses and two months of search queries to government attorneys. Google argued in federal court that the request would put both the private queries of Google users and the Mountain View giant's trade secrets at risk. A federal judge subsequently ordered Google to turn over 50,000 random copies of web pages from its index, but did not require Google to produce search-engine queries. Microsoft's MSN and Yahoo provided a sample of 1 million websites. MSN, Yahoo and AOL also provided a week of search queries. Seth Finkelstein, a programmer and civil-liberties activist, said Google's stance was "horribly self-serving. There were no privacy implications in the sense that the data was restricted to a very small set of researchers who were under various sets of protective orders," Finkelstein said. Finkelstein said Stark's findings about the prevalence of pornography on the Internet are similar to other academic studies. "What we are learning about the Internet is that it reflects life and that the Internet is not - contrary to what some people might think - more sexual than people are in general." Contact Elise Ackerman at eackerman@mercurynews.com.
The search keys which have caused people to be referred to this website haven't been at all what I expected. Thus far, AltaVista sent over someone searching for "cunt" and "spanking". Lycos sent me surfers looking for "dominatrix" and "vaginas" - as well as "Chicago" and "making lipstick from eggs." None of these words seem to refer to this site. I've also ended up with people looking for "eagles", "yaquona", "stars", "limerent", and (somewhat surprisingly) "scam investment." Also "deep thought" (!) "Stephen Hawking", "the hate page" (why me?), "frogs", "worms", "Elvis", and, (amazingly) "dirt bike freestyle". Recently I've seen "hectare to acre conversion", "wood and timber", "Companies Office", "tattoos", "rising water levels in the South Pacific", "jury service", "tornado" and "Melbourne, Australia." Frankly, I wonder how anyone ever finds what they're looking for at all. The people who stay on this website the longest have come here after searching for unusual aircraft, corpse preservation, television addiction, tattoos, card shuffling, enjo kosai, methods of capital punishment, and, incredibly, kittens.
Odd Search Keys for December 2003
Sex, News and Statistics"To date," says Ted Leonsis, "digital entertainment has been a failure." As the man who has been mainly responsible for content at AOL, the company that has tried hardest to meld the entertainment and Internet industries, he should know. The record, as far as most of the entertainment business goes, supports his gloom. But there are some areas where the two work well together. The Internet's virtues - its freedom from censorship, its speed, its low distribution costs, its global reach and its interactivity - suit some parts of the industry nicely. But only some. These include:
Why stories don't workThe entertainment companies have been trying to work out how interactivity can improve storytelling. All soaps these days, for instance, have websites where fans can touch base with their idols between episodes. Go to Dawson's Creek, and you will be offered the opportunity to chat with the assistant make-up artist on the series, or vote on whether Jen and Pacey will survive either the storm, or the summer, or neither, or both. It may help promote a soap, but it is hardly a new art form.
Directors who are looking for something more profound are struggling. Some have tried allowing audiences to choose between endings. Others have used maps, where the user clicks on different locations and pulls up a clip which shows what is happening to the story in that room. But there is a good reason why these experiments do not work. Interactivity and stories are incompatible. Stories need suspense and surprise. If the audience chooses the ending, the suspense is killed. Stories demand that the audience lose itself in the telling. If it is still capable of thinking about an alternative ending, then the story has failed. If there is the equivalent of a half-hour sitcom on the Internet, it will not come from the storytelling end of the entertainment business. More probably, it will have something to do with games. Source: The Economist 7 October 2000
Souped-Up Search EnginesFor scientists, finding the information they want on the World-Wide Web is a hit-and-miss affair. But, as Declan Butler reports, more sophisticated and specialised search technologies are promising to change all that." "What is nature?" would seem to be about as vague a question as you can get. But put it to Ask Jeeves, a popular Internet search engine, and its preferred response is clear: "Nature, international weekly journal of science". Search with other leading engines using the single keyword "nature", and Nature or its sister journals appear in the top 10 returns. Sadly, many scientific resources on the web are much harder to find. Search engines either miss them entirely, or make you scroll down dozens of pages of hits, your eyes propped open in the hope that pertinent links will leap out from the screen.
Crawling towards the answerMost search engines rely on "crawler" programs that index a web page, jump to others that this links to, index these, and so on. The starting points bias the end results, and tend to be pages on topics of mass interest - so sport is covered more extensively than quantum computing, for instance. Web pages purposely submitted to search engines - perhaps by their authors - can also gain prominence. Commercial websites, meanwhile, use a variety of tricks to boost their search rankings, filling their pages with strings of repeated keywords in a colour that makes them invisible to the viewer, or embedding keywords in the HTML (HyperText Markup Language) code that underlies a page.
If search technologies were to stand still, the phenomenal growth of the web would soon render them useless. There are already more than a billion web pages, and even the most wide-reaching search engines cover barely half of these (see above). Within two years, the web may grow to 100 billion pages, and search engines face huge difficulties keeping pace. A new study of the structure of the web provides little comfort. A study of the web's structure 5 times larger than any attempted previously reveals that it isn't the fully connected network that we've been led to believe. The study suggests that the chance of being able to surf between two randomly chosen pages is less than one in four.
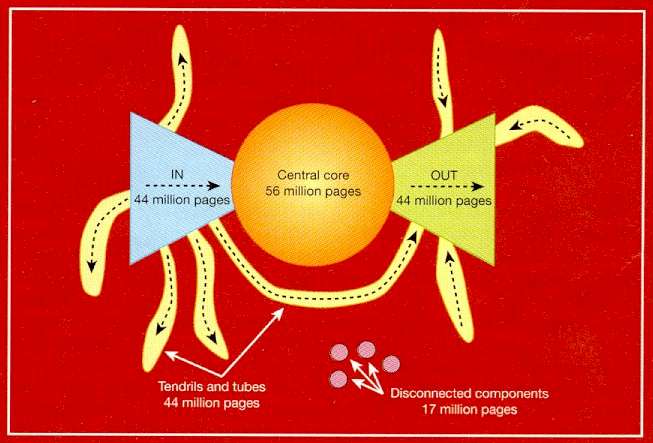
Researchers from three California groups - at IBM's Almaden Research Center in San Jose, the Alta Vista search engine in San Mateo and Compaq Systems Research Center in Palo Alto - have analysed 200 million web pages and 1.5 billion hyperlinks. Their results indicate that the web is made up of four distinct components. A central core contains pages between which users can surf easily. Another large cluster, labelled "In" contains pages that link to the core but cannot be reached from it. These are often new pages that have not yet been linked to. A separate "Out" cluster consists of pages that can be reached from the core but do not link to it, such as corporate websites containing only internal links. Other groups of pages, called "tendrils" and "tubes", connect to either the in or out clusters, or both, but not to the core, whereas some pages are completely unconnected. To illustrate this structure, the researchers picture the web as a plot shaped like a bow tie with finger-like projections. (See above figure.) This contradicts earlier suggestions that any two pages on the web are connected by a relatively small number of hyperlinks (see Nature Vol 401 p 131 1999). The implication is that search engines must crawl from a greater diversity of starting points if they are to have any hope of giving a reasonable breadth of coverage. Thankfully, new search technologies promise to increase vastly the precision of web searches - and scientists are poised to reap the benefits. The introduction of XML (eXtensible Markup Language), seen as the successor to HTML for coding web pages, should make it possible to restrict a search - for instance to scientific papers, or even to papers that report work using specific biochemical reagents. Scientific information would be easier to find on the web if it were clearly marked as such. This is the promise of XML, soon to become the language of choice for web pages. Current HTML coding tells browser programs little more than how a page should look. XML allows web pages to specify data and what they are, allowing browsers not just to read pages, but to process data referred to in the pages by machine readable tags, or "metadata." Using XML, one could, for example, state that a page is a scientific paper, and provide information such as author, address and keywords. Tags can also represent fields in a database, allowing browsers to interface directly with datasets on the web. "It would be possible to label a page as being about, say, the Viking mission to Mars, and have specific metadata attached to images that could identify them as being linked to the names of the features they depict," says Robert Miner of Geometry Technologies, a company in St Paul, Minnesota, specialising in web sites for scientific applications. Some experts are sceptical of any strategy that relies on the entire web community agreeing on formats for tagging information. But in well-organised scientific circles, it should work better. Some disciplines have already drafted their own metadata standards, such as MathML, agreed by the mathematics working group of the World Wide Web Consortium (W3C). At present, mathematical notation is usually represented on web pages using image files, but with MathML it can be described precisely. This would allow researchers to search for pages containing particular symbols. Some software developers are already developing tools that will generate the metadata automatically. The humble hypertext is also set for a facelift. The W3C is developing XLink and XPointer, which will make hyperlinks much more sophisticated. XLink will let users append their own links to pages on the web, for example, with a single link offering multiple destinations. Unlike today's hyperlinks, XPointer allows links to point to precise paragraphs or sentences, so search engines will be able to return the precise part of a document that seems relevant. Experts predict that within 5 years, searching the entire web by keywords will be a thing of the past for most researchers. Your personalised search needs may be met by dedicated science search portals. These webs within the web will concentrate many of the online resources you need within an easily navigable environment. The various online repositories of the scientific literature may by then have adopted common standards to allow seamless searching across them. And the parallel development of "intelligent" search software could mean that, as you type e-mails or word processing documents, your computer automatically delivers suggestions about relevant web resources, tailored to your particular interests and expertise. Quality, not quantityPortals are a hot topic on the web at the moment. The idea is to organise related content so that it can be searched in isolation from the web as a whole. This approach trades off the sheer scale of the available content against quality and ease of navigation. It also allows search engines that are overwhelmed by the public web to perform excellently. Popular search engines have cottoned on to the trend. The Hotbot engine, for example, lets users search only academic sites with a domain name ending in '.edu'. "Soon you will see a whole slew of search engines specialising in particular sectors," predicts Sridhar Rajagopalan (left) of IBM's Almaden Research Center in San Jose, California.
For the present, however, the biggest innovation in search engine technology takes its inspiration from the citation analyses used on the scientific literature. Conventional search engines use algorithms and simple rules of thumb to rank pages based on the frequency of the keywords specified in a query. But a new breed of engines is also exploiting the structure of the myriad links between web pages. Pages with many links pointing to them - akin to highly cited papers - are considered as "authorities", and are ranked highest in search returns.
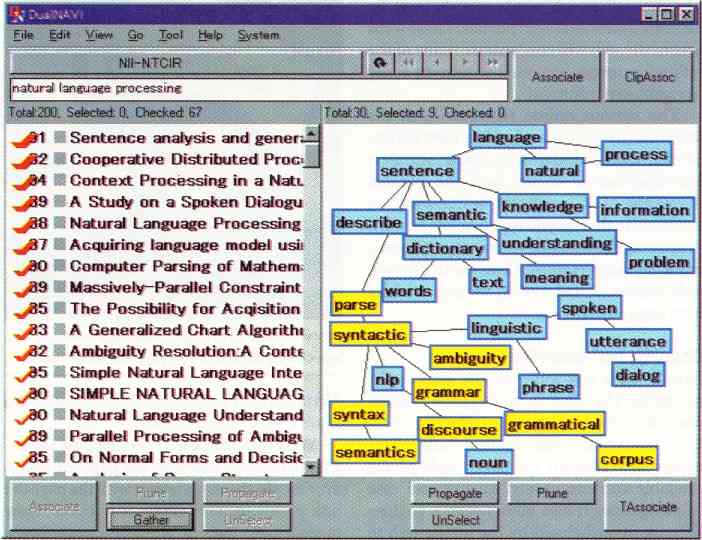
Google's algorithms rank web pages by analysing their hyperlinks in a series of iterative cycles. "We don't just look at the number of links, but where they come from," explains Brin. "A link from the Nature home page will be given more weight than a link from my home page; more things point to Nature, therefore it is likely to be more important, and more important things tend to point to Nature, which again suggests that Nature is a more important authority." Whereas most search engines only associate the text of a link with the page the link is on, Google also associates it with the page the link points to. This allows it to cover many more pages than it actually crawls, even yielding links to sites that bar search engines' crawler programs. Clever, a prototype search engine being developed at IBM Almaden, takes the citation analogy further. Like Google, it produces a ranking of authorities, but it also generates a list of "hubs", pages that have many links to authorities. Hubs are akin to review articles, which cite many top papers. Those that link to many of the most highly cited authorities are given higher rankings than those that link to less well-respected sites. "Not all links are equal," says Rajagopalan, the driving force behind Clever. Users get not only the top hits, but the hubs provide a good starting point for browsing. However, search strategies that rely on analysing hyperlinks are no panacea. New pages will have few links to them, and may be missed. And such strategies may be of little use to a scientist seeking highly specific information found on specialist sites with few incoming links. "All search engines have their weaknesses for certain queries," says Brin. Effective searching requires a mix of techniques. If you want to trawl for background information before beginning a research project, you might use an engine like Google to identify key sites, in combination with "metasearch" engines, such as SherlockHound, which allow users to query multiple search engines simultaneously. The drawback of metasearch engines is that they can give enormous lists of hits. But NEC is working on a next-generation metasearch engine, called Inquirus. Rather than simply spewing out the results from other search engines, it reindexes this initial list to provide a better ranking. Inquirus also checks for broken links, and weeds out duplicate entries. Searches for researchersBut what about search engines designed specifically for scientists? NEC's prototype, called ResearchIndex, gathers fragmented scientific resources from around the web, and automatically organises them within a citation index. And unlike most search engines, ResearchIndex retrieves PDF (portable document format) and postscript files, widely used by scientists to format manuscripts. It starts by querying dozens of popular search engines for a series of terms likely to be associated with scientific pages, such as "PDF", or "proceedings". Hundreds of thousands of scientific papers can be located quickly in this way, says Lawrence. ResearchIndex uses simple rules based on the formatting of a document to extract the title abstract, author and references of any research paper it finds. It recognises the various forms of presenting bibliographies, and by comparing these with its database of other articles can conduct automatic citation analyses for all the papers it indexes. This information can also be used to quickly identify articles related to any indexed paper. The prototype form of ResearchIndex is being applied to the computer sciences. Its archive of papers in this subject alone, at 270,000 articles, is bigger than leading online scientific archives such as the Highwire Press, which has almost 150,000 articles, and the Los Alamos archive of physics preprints, which contains about 130,000 papers. The engine already has an enthusiastic following among computer scientists. Stevan Harnad of the University of Southampton, who has tested the system on his CogPrints archive of preprints in the cognitive sciences, is another convert. "For the literature it covers, it is a gold mine," he says. NEC is giving the software free to noncommercial users, and Lawrence hopes it will be applied across many disciplines: "Our goal is to not just create another digital library of scientific literature, but to provide algorithms, techniques and software that can be widely used to help improve communication and progress in science." Concept albumsOther prototype search engines boast features that could make trawling the scientific literature more efficient. A team at Hitachi's Advanced Research Laboratories, in Hatoyama, Japan, is developing an engine called DualNAVI which could improve the efficiency of searches on collections of scientific literature such as Medline. Hits for a keyword are listed on the left-hand side of the screen. But DualNAVI also generates a set of related keywords by analysing the retrieved documents, and displays these on the right of the screen as a "topic word graph" (see below). Click any topic, and related documents are highlighted in the left-hand window. This often yields articles that the initial query missed. And in a further twist, groups of documents can be selected, indexed for keywords, and run against other literature databases to find related papers.
Collexis, a Dutch firm based in Hague, has taken this approach further by developing algorithms that can analyse documents not just for keywords but for "concepts". Taking its guide from thesauri such as the US National Library of Medicine's Unified Medical Language System, which recognises more than 600,000 different biomedical concepts, Collexis's engine looks for defined patterns of terms and analyses their contextual relationships. Users can paste any text, such as a scientific paper, into a search box. This is automatically analysed to identify its major concepts, creating a profIle that is then used to search for similar texts. Collexis also allows users to fine-tune their searches by adjusting the weighting given to each individual concept. Because the Collexis engine's concept matching does not depend on a document's precise grammatical structure, it can generate concepts for texts in many languages, based on a rough machine translation of a document's keywords. Indeed, the software was developed as part of a European Union-funded project to facilitate international cooperation between health researchers. In keeping with these origins, 20% of Collexis's profits will go to promoting collaboration between medical researchers in developed and developing countries. Autonomy, a San Francisco-based company, is also using concepts. It generates these using neural networks and pattern matching technologies developed at the University of Cambridge. Rather than simply responding to specific queries, however, Autonomy is developing programs that automatically analyse any text in an active window on a user's screen to suggest related web resources. The company has released a free, pared-down version of its software, called Kenjin. As you type, Kenjin continuously proposes web resources in a small window at the bottom of the screen. This is still rudimentary, but gives a pointer to the future. Google's Brin predicts that in 5 years the search engine as we know it will no longer exist, or be marginal. In its place will come 'intelligent' programs that search by using their experience of the needs and interests of their users. Rajagopalan agrees: "In future there will be automatic feedback loops based on what search results you have selected in the past in relation to this or that query, or how long you stayed at particular web pages." Learning from previous search sessions, such programs may, in the manner of Autonomy's program, continuously conduct background searches and suggest web resources - with these being tailored to the interests of individual users. Such automated technologies should also help solve one of the biggest limitations to efficient searching: the fact that most people don't frame their queries to maximise the relevance of search returns.
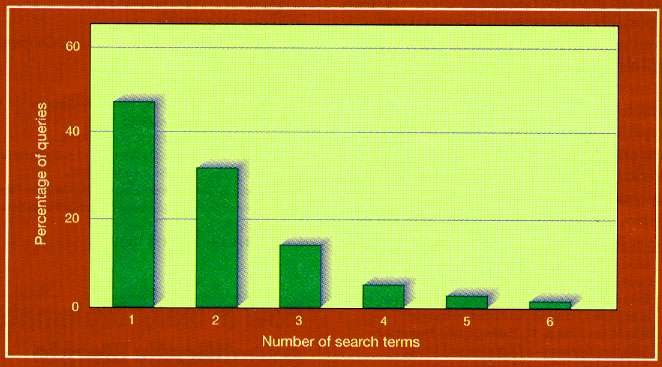
As search engines become ever more sophisticated, human inadequacies are becoming the biggest limiting factor. A survey by the NEC Research Institute in Princeton, New Jersey, reveals that up to 70% of web users typically type in only one keyword or search term. This is a recipe for obtaining long lists irrelevant hits. Yet even among the staff of the NEC Research Institute, who should be web-savvy, almost half fail to define their searches more precisely. Statistics such as these have convinced search engine developers that there is little point trying to get users to read the "search tips" or to use the advanced search options provided by most search engines. To address this problem, more sophisticated engines are now building classifications hidden behind the search interface, which allow them to prompt for more information when presented with ambiguous search terms. Asked to search for "green", for example, the engine might ask whether the user wants to search for green beans, green parties, and so on. As search technologies improve, journal publishers and the operators of electronic preprint archives are also taking steps that should make it much easier to search for scientific papers on the web. Crossref, a scheme agreed to at the end of 1999 by leading commercial scientific publishers, will link references in the articles they publish to the source papers in their respective publications (see Nature Vol 402 1999). More than three million articles across thousands of journals will become searchable this year, with half a million being added every year thereafter. And in February, the operators of the world's leading archives of electronic preprints, or "e-prints", agreed standard formats that should allow scientists to search across all of them simultaneously. This Santa Fe Convention will allow e-prints to be tagged as "refereed" or "unrefereed", along with other information such as author and keywords. Using software that will become available this month, any scientist could, in principle, set up an e-print or refereed website, or a site of conference proceedings, in the knowledge that it would be compatible with this global system. If these efforts succeed in weaving a seamless web from the scientific literature, researchers should find that the hours spent trawling through pages of irrelevant search returns are consigned to history. Search EnginesAltaVista altavista.com Advanced Search EnginesGoogle google.com Metasearch EngineSherlockHound sherlockhound.com Automated Search ToolsAutonomy autonomy.com StandardsW3C XML Page w3.org/XML/Activity Source: Nature Vol 405 11 May 2000
Not all search services are "true" search engines that crawl the web. For instance, Yahoo and the Open Directory both are "directories" that depend on humans to compile their listings. In fact, most of the services below offer both search engine and directory information, though they will predominately feature one type of results over the other. AOL Search search.aol.com - AOL Search allows its members to search across the web and AOL's own content from one place. The "external" version does not list AOL content. The main listings for categories and web sites come from the Open Directory (see below). Inktomi also provides crawler-based results, as backup to the directory information. Before the launch of AOL Search in October 1999, the AOL search service was Excite-powered AOL NetFind. AltaVista altavista.com - AltaVista is consistently one of the largest search engines on the web, in terms of pages indexed. Its comprehensive coverage and wide range of power searching commands makes it a particular favourite among researchers. It also offers a number of features designed to appeal to basic users, such as "Ask AltaVista" results, which come from Ask Jeeves (see below), and directory listings primarily from the Open Directory. AltaVista opened in December 1995. It was owned by Digital, then run by Compaq (which purchased Digital in 1998), then spun off into a separate company which is now controlled by CMGI. Ask Jeeves askjeeves.com - Ask Jeeves is a human-powered search service that aims to direct you to the exact page that answers your question. If it fails to find a match within its own database, then it will provide matching web pages from various search engines. The service went into beta in mid-April 1997 and opened fully 1 June 1997. Results from Ask Jeeves also appear within AltaVista. Direct Hit directhit.com - Direct Hit is a company that works with other search engines to refine their results. It does this by monitoring what users click on from the results they see. Sites that get clicked on more than others rise higher in Direct Hit's rankings. Thus, the service dubs itself a "popularity engine." Direct Hit's technology is currently best seen at HotBot. It also refines results at Lycos and is available as an option at LookSmart and MSN Search. The company also crawls the web and refines this database, which can be viewed via the link above. Excite excite.com - Excite is one of the most popular search services on the web. It offers a medium-sized index and integrates non-web material such as company information and sports scores into its results, when appropriate. Excite was launched in late 1995. It grew quickly in prominence and consumed two of its competitors, Magellan in July 1996, and WebCrawler in November 1996. These continue to run as separate services. FAST Search alltheweb.com - Formerly called All The Web, FAST Search aims to index the entire web. It was the first search engine to break the 200 million web page index milestone. The Norwegian company behind FAST Search also powers the Lycos MP3 search engine. FAST Search launched in May 1999. Go / Infoseek go.com - Go is a portal site produced by Infoseek and Disney. It offers portal features such as personalisation and free e-mail, plus the search capabilities of the former Infoseek search service, which has now been folded into Go. Searchers will find that Go consistently provides quality results in response to many general and broad searches, thanks to its ESP search algorithm. It also has an impressive human-compiled directory of websites. Go officially launched in January 1999. It is not related to GoTo, below. The former Infoseek service launched in early 1995. GoTo goto.com - Unlike the other major search engines, GoTo sells its main listings. Companies can pay money to be placed higher in the search results, which GoTo feels improves relevancy. Non-paid results come from Inktomi. GoTo launched in 1997 and incorporated the former University of Colorado-based World Wide Web Worm. In February 1998, it shifted to its current pay-for-placement model and soon after replaced the WWW Worm with Inktomi for its non-paid listings. GoTo is not related to Go (Infoseek). Google google.com - Google is a search engine that makes heavy use of link popularity as a primary way to rank websites. This can be especially helpful in finding good sites in response to general searches such as "cars" and "travel," because users across the web have in essence voted for good sites by linking to them. HotBot hotbot.com - Like AltaVista, HotBot is another favourite among researchers due to its large index of the web and many power searching features. In most cases, HotBot's first page of results comes from the Direct Hit service (see above), and then secondary results come from the Inktomi search engine, which is also used by other services. It gets its directory information from the Open Directory project (see below). HotBot launched in May 1996 as Wired Digital's entry into the search engine market. Lycos purchased Wired Digital in October 1998 and continues to run HotBot as a separate search service. IWon iwon.com - Backed by US television network CBS, iWon has a directory of web sites generated automatically by Inktomi, which also provides its more traditional crawler-based results. iWon gives away daily, weekly and monthly prizes in a marketing model unique among the major services. It launched in autumn 1999. Inktomi inktomi.com - Originally, there was an Inktomi search engine at UC Berkeley. The creators then formed their own company with the same name and created a new Inktomi index, which was first used to power HotBot. Now the Inktomi index also powers several other services. All of them tap into the same index, though results may be slightly different. This is because Inktomi provides ways for its partners to use a common index yet distinguish themselves. There is no way to query the Inktomi index directly, as it is only made available through Inktomi's partners with whatever filters and ranking tweaks they may apply. LookSmart looksmart.com - LookSmart is a human-compiled directory of web sites. In addition to being a stand-alone service, LookSmart provides directory results to MSN Search, Excite and many other partners. AltaVista provides LookSmart with search results when a search fails to find a match from among LookSmart's reviews. lookSmart launched independently in October 1996, was backed by Reader's Digest for about a year, and then company executives bought back control of the service. Lycos lycos.com - Lycos started out as a search engine, depending on listings that came from spidering the web. In April 1999, it shifted to a directory model similar to Yahoo. Its main listings come from the Open Directory project, and then secondary results come from either Direct Hit or Lycos' own spidering of the web. In October 1998, Lycos acquired the competing HotBot search service, which continues to be run separately. MSN Search search.msn.com - Microsoft's MSN Search service is a LookSmart-powered directory of web sites, with secondary results that come from AltaVista. RealNames and Direct Hit data is also made available. MSN Search also offers a unique way for Internet Explorer 5 users to save past searches. Netscape Search search.netscape.com - Netscape Search's results come primarily from the Open Directory and Netscape's own "Smart Browsing" database, which does an excellent job of listing "official" web sites. Secondary results come from Google. At the Netscape Netcenter portal site, other search engines are also featured. Northern Light northernlight.com - Northern Light is another favourite search engine among researchers. It features one of the largest indexes of the web, along with the ability to cluster documents by topic. Northern Light also has a set of "special collection" documents that are not readily accessible to search engine spiders. There are documents from thousands of sources, including newswires, magazines and databases. Searching these documents is free, but there is a charge of up to $4 to view them. There is no charge to view documents on the public web - only for those within the special collection. Northern Light opened to general use in August 1997. Open Directory dmoz.org - The Open Directory uses volunteer editors to catalog the web. Formerly known as NewHoo, it was launched in June 1998. It was acquired by Netscape in November 1998, and the company pledged that anyone would be able to use information from the directory through an open license arrangement. Netscape itself was the first licensee. Lycos and AOL Search also make heavy use of Open Directory data, while AltaVista and HotBot prominently feature Open Directory categories within their results pages. Snap snap.com - Snap is a human-compiled directory of web sites, supplemented by search results from Inktomi. Like LookSmart, it aims to challenge Yahoo as the champion of categorising the web. Snap launched in late 1997 and is backed by Cnet and NBC. WebCrawler webcrawler.com - WebCrawler has the smallest index of any major search engine on the web - think of it as Excite Lite. The small index means WebCrawler is not the place to go when seeking obscure or unusual material. However, some people may feel that by having indexed fewer pages, WebCrawler provides less overwhelming results in response to general searches. WebCrawler opened to the public on 20 April 1994. It was started as a research project at the University of Washington. America Online purchased it in March 1995 and was the online service's preferred search engine until Nov 1996. That was when Excite, a WebCrawler competitor, acquired the service. Excite continues to run WebCrawler as an independent search engine. Yahoo yahoo.com - Yahoo is the web's most popular search service and has a well-deserved reputation for helping people find information easily. The secret to Yahoo's success is human beings. It is the largest human-compiled guide to the web, employing about 150 editors in an effort to categorise the web. Yahoo has over 1 million sites listed. Yahoo also supplements its results with those from Inktomi. If a search fails to find a match within Yahoo's own listings, then matches from Inktomi are displayed. Inktomi matches also appear after all Yahoo matches have first been shown. Yahoo is the oldest major web site directory, having launched in late 1994. Source: the web
For IT-related articles on snooping, usage, the future, e-diaries, piracy, flickers, cyborgs, browsing, trends, jokes, philosophic agents, artificial consciousness and more, press
the "Up" button below to take you to the Index page for this Information and Technology section. |

 Today's mainstream search engines are simply not run with scientists in mind. Leaving aside
their inability to interrogate the vast amount of scientific information held in databases - be they of spectral lines of stars, genome data or events from particle
colliders - scientists are poorly served even when they search for text on the web. "There are substantial limitations to search engines and they have bigger implications for
scientists than for regular consumers," observes Steve Lawrence (right) of the NEC Research Institute in Princeton, New Jersey, co-author of a seminal paper on the accessibility of
online information (see Nature Vol 400 p 107 1999).
Today's mainstream search engines are simply not run with scientists in mind. Leaving aside
their inability to interrogate the vast amount of scientific information held in databases - be they of spectral lines of stars, genome data or events from particle
colliders - scientists are poorly served even when they search for text on the web. "There are substantial limitations to search engines and they have bigger implications for
scientists than for regular consumers," observes Steve Lawrence (right) of the NEC Research Institute in Princeton, New Jersey, co-author of a seminal paper on the accessibility of
online information (see Nature Vol 400 p 107 1999).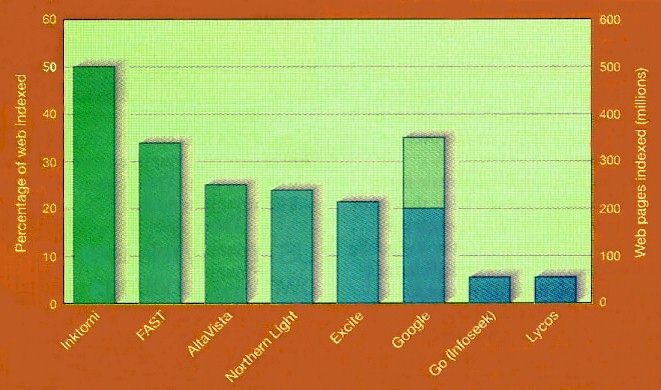

 This approach has been pioneered by Sergey Brin (on the right) and Lawrence Page (on the left),
two graduate students in computer science at Stanford University in California. In less than a year, their Google search engine has become the most popular on the web, yielding
more precise results for most queries than conventional engines - and transforming the lives of its developers. "I haven't finished my Phd," says Brin. "I've been too busy
with Google."
This approach has been pioneered by Sergey Brin (on the right) and Lawrence Page (on the left),
two graduate students in computer science at Stanford University in California. In less than a year, their Google search engine has become the most popular on the web, yielding
more precise results for most queries than conventional engines - and transforming the lives of its developers. "I haven't finished my Phd," says Brin. "I've been too busy
with Google."